

Is it more expensive to use AI in Spanish?
Yes, the price depends on what language you use. Seriously!


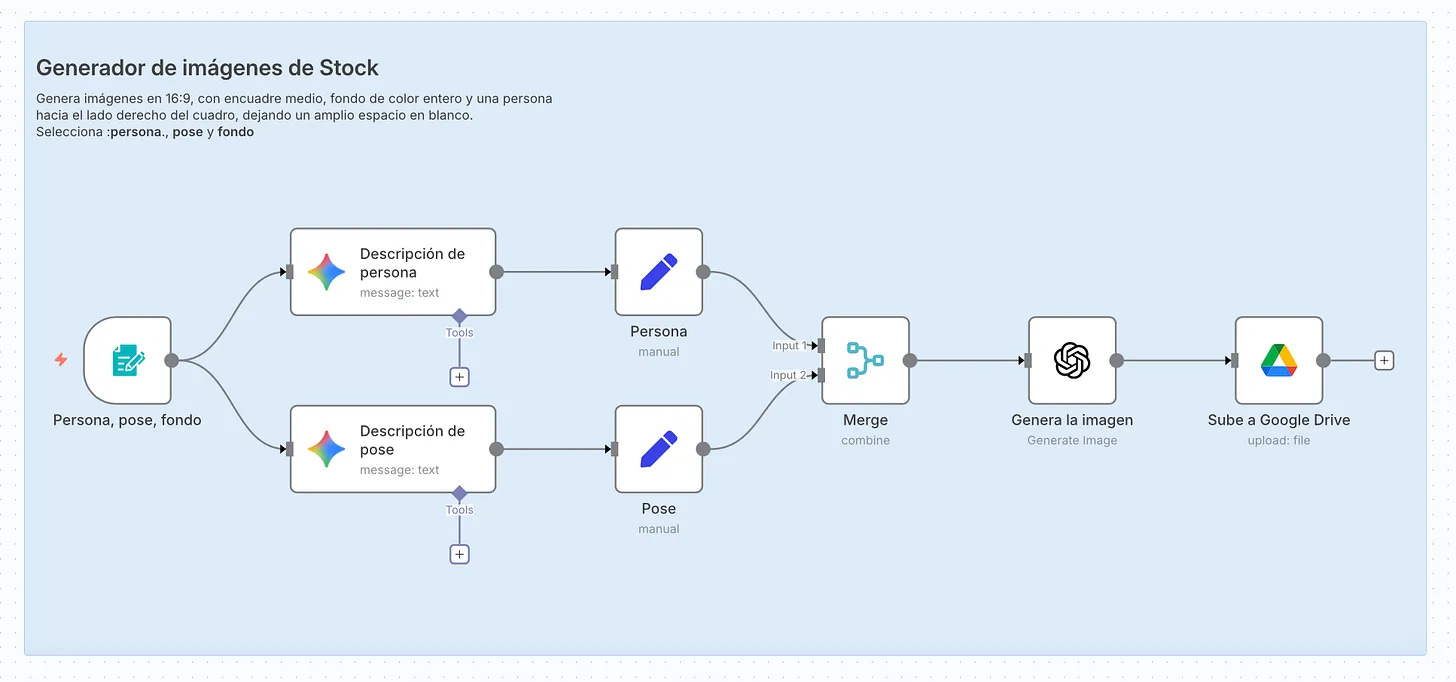
So, here’s what I‘ve been up to lately. I’ve been playing around with n8n, a very cool automation platform. It’s basically a tool that lets you connect different apps and create automated workflows.
For example, I built this workflow where you input three things: a character, the character’s pose and a background color. With that info, a language model (Gemini) improves the character and pose descriptions, then ChatGPT creates a stock-style photo and it gets saved in Google Drive. Everything happens automatically, step by step, no code required.
If you are curious about what kind of images this workflow creates, here are a couple of examples:


Nice, right?
I’m not telling you this to show off (ok, maybe just a little 😊), but because it’s an easy way to see how apps actually talk to AI.
Here is the thing: to generate each image, I’m not paying ChatGPT or Google $20 a month. Each image costs me cents.
What’s really mind-blowing here isn’t the images (though I’ll admit I’m pretty proud of that workflow). What’s mind-blowing is that Google and OpenAI charge me more for using Spanish than English.
That’s what this post is about.
Wait, they charge you per word? Per word?!
Yes, they charge you per word. Well… sort of, let me explain.
Systems don’t “chat” with LLMs like ChatGPT or Claude the way humans do. Instead of using the web interface or mobile app, systems use something called an API (application programming interface), basically a way to talk to LLMs through code.
And this difference in how you access the model changes how you get charged. With the API, you don’t pay a monthly subscription (it’s not Netflix). You pay for the information you process.
Every time you send text to the AI using the API, they charge you. This makes sense since the text you send needs to be analyzed and responded to, which requires servers, electricity, processing time, all that stuff. It’s like your electric bill: the more you use, the more you pay (damn electric kettle).
To charge you, these companies need a way to “measure” how much text gets used when we interact with the model. For us humans, it’s natural to think in words, but machines work a bit differently. Instead of words, they use something called tokens.
Think of tokens as the smallest unit of text an LLM can understand. Usually part of a word or even punctuation marks and spaces.
When you send text to the AI, it breaks it down into tokens, processes them and uses tokens to generate the response. At the end, you get charged based on the total number of tokens used in that interaction (for both your question and the model’s response). Simple, right?
It’s like if Netflix charged us per megabyte of streaming. If we watch a (insert your favorite series here) marathon, we’d pay more than if we just watched a single movie.
So far so good, but here’s the thing with tokens… the amount you use depends on your language.
So some languages are more “expensive” than others?
¡Sí señor! Some languages are more expensive than others.
Let’s test it by counting tokens in different phrases. To do this, I’m going to use OpenAI’s tool called Tokenizer, which tell us how many tokens are in a text. You can try it yourself here, or do what I did and write a little Python script to count tokens (I know, sometimes I’m a bit of a nerd :P).
I started with something super simple:
Spanish: “Gracias” → 2 tokens
English: “Thanks” → 1 token
Portuguese: “Obrigado” → 3 tokens
Japanese: “ありがとう” → 1 token
Apparently being polite in Spanish costs twice as much as in English or Japanese, though we’re doing a bit better than Portuguese. (BTW, I ran all these experiments using GPT-4 tokenizer).
What about a more complex sentence?
Spanish: “Tengo sed, creo que iré por una cerveza.” → 14 tokens
English: “I’m thirsty, I think I’ll go for a beer.” → 13 tokens
Ok, it’s only one extra token in Spanish, so we can’t say it’s that much more expensive… but it all adds up, and those beers aren’t free ;)
And while we’re at it, let’s make the phrase more complex by asking about food:
Spanish:
“Haz una búsqueda en Internet sobre platos de cocina peruana y dime el top 5 para un paladar extranjero.” → 26 tokensEnglish:
“Do an internet search about Peruvian dishes and tell me the top 5 for a foreign palate.” → 20 tokens
Now you can see the difference between languages more clearly, asking the question in Spanish costs 30% more. And that’s nothing, there are languages that use way more tokens than Spanish. For example Arabic, Thai and, (winning the gold medal) Burmese.
Here’s the same example about Peruvian dishes in those languages:
Arabic:
“ابحث في الإنترنت عن أطباق المطبخ البيروفي وأخبرني بأفضل خمسة أطباق تناسب ذوق الأجانب.” → see? 62 tokens!!!Thai:
“ลองค้นหาในอินเทอร์เน็ตเกี่ยวกับอาหารเปรู แล้วบอกฉัน 5 อันดับที่เหมาะกับรสนิยมของชาวต่างชาติ” → and here 82 tokens!!!Burmese:
“အင်တာနက်မှာ ပီရူးအစားအစာတွေကို ရှာဖွေပြီး နိုင်ငံခြားစားသမားတွေအတွက် ထိပ်တန်း ၅ မျိုးကို ပြောပေးပါ။” → world record, at 193 tokens!!!!
See what I mean? Depending on what language you speak, interacting with an AI doesn’t cost the same. You’re fine if you do it in English, it’s a bit pricier in Spanish, and it can end up being 3, 4, or even almost 10 times more expensive in other languages!
And I don’t even have to look that far. Right here in Peru, we speak other languages besides Spanish, like Quechua and Aymara.
Let’s try the same example:
Aymara: “Internet tuqina Piruw manq’añanak thaqhata, markanakar chhijllatirinakapa amtäwi layku phisqha nayrïri sum manq’añanak qhanañcht’asma.” → 58 tokens
Quechua: “Internetpi Piruw mikhunakunata maskhay, huk watuq runapaq aswan sumaq 5 mikhunata willaway” → 33 tokens
Keep in mind that these extra tokens don’t just apply to your prompt. They also apply to the AI’s response. This clearly doesn’t help democratize access to this technology around the world :(
So is the AI optimized for English speaking?
In short, yes. But it’s not on purpose, it’s a consequence of how these systems are built.
To explain this, let’s start by talking about how tokens are generated.
The tokenizer
As much as it might sound like one, the tokenizer isn’t some product you’ll find on a TV sales channel next to the “Jack LaLanne Power Juicer” (am I the only one who spent their childhood watching those?).
A tokenizer is the part of a language model that converts text into smaller units called tokens.
Basically, it reviews millions of texts and looks for patterns that repeat. For example, if it sees the letters “e-s-c-r-i-b-i-e-n-d-o” it will search for which chunks of that letter combination repeat most frequently in its training data. In this case, it finds that “e-s”, “c-r-i”, “b-i”, “e-n-d-o” repeat often, so it breaks that word into tokens.

Now that we know how these tokens are generated, let me tell you the two reasons why AI is “optimized” for English.
English is more compact
This language generally uses shorter words. For example they say “cat”, we “gato”; we say “comida” (3 syllables!) and they say “food”.
On top of that, Spanish has so many conjugations that often English speakers trying to learn the language get migraine. “hablo,” “hablas,” “habla,” “hablamos,” “habláis,” “hablan,” “hablé,” “hablaste,” “hablaríamos”… you get me. In English, you basically have “speak,” “speaks,” and “spoke.” Fewer variants, fewer tokens.
Tokenizers are trained on data
Ok! If you noticed, when I explained how a tokenizer works, I elegantly avoided explaining its training data. Well, no escaping it now.
You can think of training data as a mountain of text that includes books, articles, news, web pages, poems, reggaeton songs, etc.
Our friend, the tokenizer, reads it all over and over again looking for patterns about which letters appear together most often. By the end of the process, it’s established which letter combinations that appear together will become tokens.
Now here comes the plot twist… 90% of the texts used to train the tokenizer are in English!! So obviously the patterns it finds more often are from that language, making it the most efficient one.
This language difference also impacts the quality of the responses the AI gives us, but before we get to that, I want to show you a beautiful coincidence I just discovered. My name has the same number of tokens as Obi-Wan Kenobi’s (must be a sign from the universe).

And on top of that, the responses aren’t as good in other languages?
Exactly! But don’t get me wrong, they’re not bad. Give me a minute to explain the two reasons why they’re not quite as good as in English.
More tokens make it harder to understand
Remember how my question about Peruvian food used 20 tokens in English, 26 in Spanish, and then shot up to 58 in Aymara, 82 in Thai, and 193 in Burmese?
Well, the more tokens there are to process, the harder it is for the AI to get the full context of what you’re saying (plus it’s more expensive). Think of it like your AI having to interpret more information pieces to understand the same idea.
It’s not really as multilingual as it seems
Remember that mountain of training data, and how 90% of it was in English?
That means while it understands all languages, it has waaaay more experience with English patterns, context, and nuances. Plus, when we’re talking about really niche knowledge, chances are its only sources are in English, so it’ll respond better in that language.
It’s not that the AI’s responses in other languages are bad, honestly, they’re pretty good. It’s just that English responses are a little bit better. And when you add the fact that these responses cost more in other languages, well... that’s where we are.
What you pay for AI depends on your language
Yes, when you use these language models through their API.
Obviously not if you’re on a monthly subscription. Either way, I think it’s really important to understand this difference.
We know it’s not some conspiracy (do we? :P), and it’s not like the people who designed these systems are evil. It’s simply how this technology works and how much data exists in different languages around the world.

The reality is that if you’re one of us who speaks Spanish, French, Quechua, Thai, or some other language that isn’t English, we’re going to use more tokens and end up paying more to use our favorite AI. Not to mention the responses will not as good as in English.
AI companies are very aware of this limitation and are actively working to close the gap. They’re improving their tokenization models and trying to better represent other languages in their training data. So I’m hopeful this will get better over time, though I’m not sure if the gap will ever completely disappear.
There are some strategies to try to work around this, like speaking to the AI in English (something I usually do) or asking the AI itself to translate before responding.
None of these solutions is perfect. And while I’ll say again that responses in your language are really good, it’s important to understand the limitations we’re dealing with when we use this technology.
And that’s it, hope you enjoyed the post :)
I just have one more thing to say...
One more thing (off topic)
I’ve been checking out ChatGPT’s recommendations in different languages for the top 5 Peruvian dishes. They’re good, but since we’re here, I wanted to give you the 5 I think you should actually try :P.
So find your neighborhood Peruvian restaurant and tell them Germán recommended you try:
Ceviche: Can’t miss this one. Try both the fish and octopus versions. (Goes perfectly with an ice-cold beer).
Cau-cau: I know, it’s tripe (not for everyone), but it’s my favorite dish and I couldn’t leave it out. There are different recipes. If you’re brave enough to order it, make sure they don’t put peas or carrots in it. Served with rice.
Seco de cabrito: It’s amazing. They have to serve it with beans, rice, a little green tamale, and zarza criolla. (Otherwise it doesn’t count).
Papa rellena: You can’t imagine what this is. Take the chance to order some Peruvian sauces to go with it, like Huancaína or Ocopa.
Anticuchos: Our street food. Yes, it’s grilled beef heart marinated in ají panca and spices.
Extra points if you try these dishes (medal of valor if you try the cau-cau).
Best,
G
Hi German, (sorry I can't do the accent on your name!), muchas gracias! That's kind of a stunning situation and yet another way in which the non-English-speaking world is disadvantaged - and the English-speaking world continues to be oblivious to the multitude of challenges for the rest of the world in so many respects. Most people do not know how much context and subtlety we miss when we are stuck using translation apps and AI's algorithms. Just in the process of trying to communicate with someone without the help of google translate, we are developing a relationship with the person and their culture. By relying on it, how much more of our humanity are we giving up for the ease of AI?! And how can we work with it without being afraid of a negative influence? I am really eager to learn more and consider how these issues could be brought into the public eye. It's such an important topic if we all truly want to gain a better understanding of the broader world - for all of our benefit!